Drowning in AI Code Review Noise? A Framework to Measure Signal vs. Noise
Most AI code review tools generate 10-20 comments per PR. The problem? 80% are noise. Here's a framework for measuring signal-to-noise ratio in code reviews - and why it matters more than you think.
TL;DR: Think this post has low signal-to-noise ratio? Here’s the framework, then you decide:
How to measure AI code review quality (30 seconds):
Every comment falls into 3 tiers by severity:
- Tier 1: Would cause production failures (crashes, breaking changes, security holes)
- Tier 2: Would cause maintainability issues (architectural violations, performance regressions)
- Tier 3: Subjective noise (style suggestions, “consider using const here”)
Signal Ratio = (Tier 1 + Tier 2) / Total. If <60%, your tool is a noise generator.
The challenge: Section 4 analyzes 3 real PRs. One tool left 14 comments, missed every critical bug (21% signal). Another left 18 comments, caught a bug that would crash the entire job scheduler (61% signal). Now ask: would YOUR tool have caught it? If you don’t know, keep reading. If you’re sure it would, you’re either using a great tool or fooling yourself ^-^
The Industry’s Dirty Secret
You open a PR. Your AI code review tool leaves 15 comments:
- “Consider making this timeout configurable”
- “Remove unused theme variable”
- “Use theme values for consistency”
- “Remove unnecessary optional chaining”
- “Consider memoizing headers”
- …10 more suggestions
Somewhere in there are 2 critical bugs that would crash production. Will you find them?
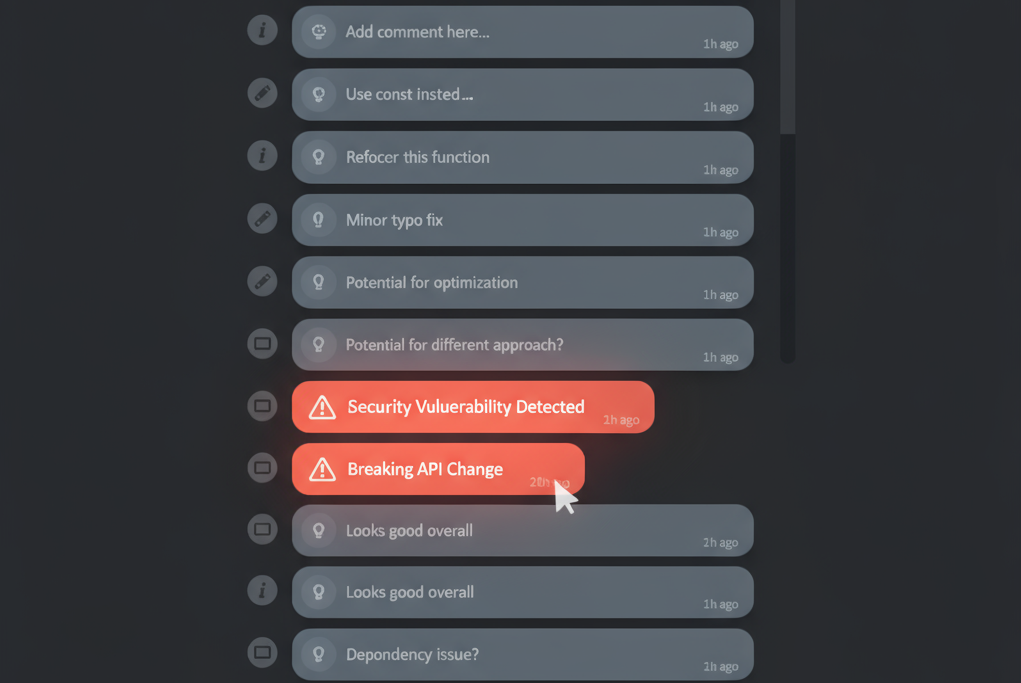 Critical bugs hidden among trivial suggestions - the core problem of noisy AI reviews
Critical bugs hidden among trivial suggestions - the core problem of noisy AI reviews
Research analyzing 22,000+ AI code review comments across 178 repositories found that concise, focused comments were far more likely to lead to actual code changes [2].
Translation: when you spam developers with suggestions, they ignore everything—including the critical ones.
The DORA research program found that organizations shortening code review times see better delivery performance. Excessive review overhead, including noisy AI suggestions, directly harms team velocity [4].
The problem isn’t that AI tools don’t work. It’s that they work too much.
What “Low Noise” Actually Means
Low noise doesn’t mean fewer comments. It means higher signal-to-noise ratio.
A good AI code review tool should catch:
- Critical bugs (memory leaks, race conditions, null pointer exceptions)
- Architectural inconsistencies (pattern violations, breaking changes)
- Security vulnerabilities (injection risks, authentication bypasses)
It should NOT spam you with:
- Style suggestions (“this variable name could be better”)
- Micro-optimizations (“consider using const here”)
- Subjective opinions (“this could be refactored”)
Every comment should be worth interrupting a developer’s flow. If it’s not, it’s noise [3].
A Framework for Measuring Signal-to-Noise Ratio
The industry lacks a standardized way to measure AI code review quality.
Here’s a framework anyone can use to evaluate any tool:
The Three-Tier Classification
Tier 1 (Critical Signal): Issues that would cause observable failures
- Runtime errors (crashes, exceptions, undefined behavior)
- Breaking changes (API changes, data structure changes)
- Security vulnerabilities (exploitable, not theoretical)
Tier 2 (Important Signal): Issues that violate established patterns
- Architectural inconsistencies
- Performance degradation (measurable)
- Maintainability risks (technical debt)
Tier 3 (Noise): Everything else
- Style suggestions
- Subjective opinions
- Micro-optimizations without measurable impact
The Metric: Signal Ratio
Signal Ratio = (Tier 1 + Tier 2 findings) / Total comments
A good tool should have Signal Ratio > 60%.
A great tool should have Signal Ratio > 80%.
This framework provides a clear, objective way to measure the effectiveness of any AI code review tool. It ensures that tools prioritize actionable, high-impact feedback over sheer volume.
Applying the Framework: Three Real-World Tests
Let’s apply this framework to evaluate two tools: CodeRabbit and LlamaPReview. These examples are based on real PRs from the open-source project bluewave-labs/Checkmate.
Case 1: The Silent Killer PR #3044 - 21 lines
What changed: Added DNS caching and staggered monitor starts to improve network resilience.
CodeRabbit’s review:
- 1 suggestion about making timeout values configurable
- Focus: best practices and flexibility
LlamaPReview’s review:
- 6 suggestions, including 2 Tier 1 critical issues:
- Runtime bug:
addJob(monitor)called with 1 argument, but the function signature expects 2 arguments(monitorId, monitor). This would causemonitorId.toString()to fail, breaking the entire job scheduling system. - Architecture issue: Global DNS cache could serve stale resolutions in long-running processes, affecting all HTTP services.
- Runtime bug:
Signal Ratio:
- CodeRabbit: 0/1 = 0%
- LlamaPReview: 2/6 = 33% (critical issues prioritized)
Case 2: Death by a Thousand Cuts PR #3005 - 493 lines
What changed: Implemented a new uptime monitors page with tables, charts, and status visualization.
CodeRabbit’s review: 10 suggestions, mostly Tier 3 noise:
- “Remove unused
themevariable” - “Use theme values for consistency”
- “Remove unnecessary optional chaining”
- “Add proper type for Redux state”
- …6 more style-related suggestions
LlamaPReview’s review: 6 suggestions, including 2 Tier 1 critical issues:
- Runtime bug: Histogram component mixes Check objects with “placeholder” strings. When tooltip tries to access
placeholder.responseTime, it crashes. - React bug: Table uses
Math.random()for keys, causing unnecessary re-renders and potential UI state loss.
Signal Ratio:
- CodeRabbit: 0/10 = 0%
- LlamaPReview: 2/6 = 33%
Case 3: When Both Tools Shine PR #2999 - 237 lines
What changed: Added superadmin password reset functionality.
CodeRabbit caught:
- Missing self-password reset prevention (security rule)
- Error propagation issues (UX)
LlamaPReview caught:
- Breaking API change:
useEditUsernow returns 4 values instead of 3, breaking all existing consumers - Validation mismatch: client sends
{password, confirm}, server expects{password, newPassword}
Signal Ratio:
- CodeRabbit: 2/3 = 67%
- LlamaPReview: 3/6 = 50%
Why Achieving High Signal Ratio Is Hard
This isn’t a skill issue. It’s a fundamental architecture problem.
Most AI tools optimize for recall (catching everything), not precision (catching what matters).
The result? 60-80% false positive rates [1], [3].
Design Principles for High Signal Ratio
To achieve high signal ratio, any tool must:
- Filter by Impact: Only flag issues that cause observable harm.
- Understand Context: Check patterns across the codebase before flagging.
- Resist Overreporting: Trust that fewer, actionable comments are better.
The Data: Why This Matters
Research on 22,000+ AI code review comments found [2]:
- ✅ Concise comments → 3x more likely to be acted upon
- ✅ Hunk-level tools (focused reviews) → outperform file-level tools
- ✅ Manually-triggered reviews → higher adoption than automatic spam
DORA research confirms: shorter code review times correlate with better delivery performance. Noise directly harms velocity [4].
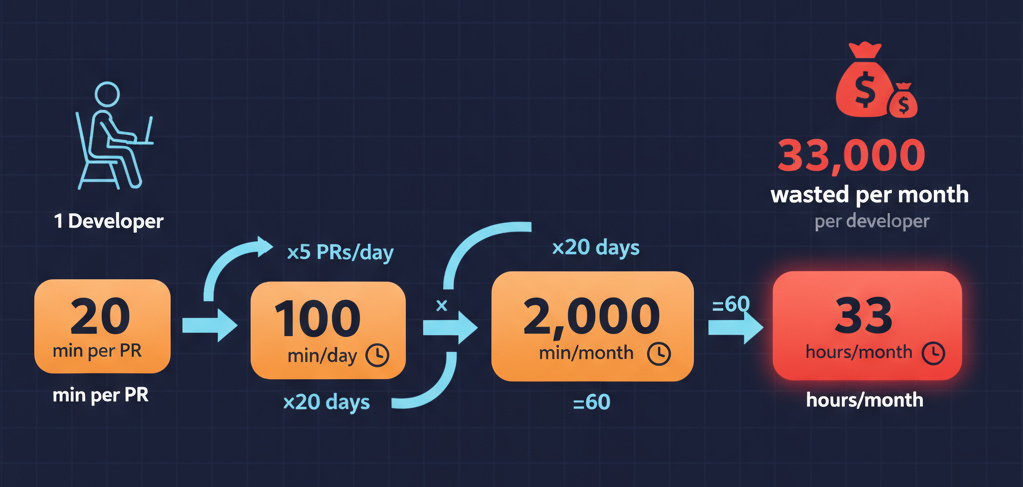 The hidden cost: 33 hours per developer per month spent filtering noise
The hidden cost: 33 hours per developer per month spent filtering noise
The business impact is real: If developers spend 20 minutes per PR filtering noise (5 PRs/day), that’s 33 hours per month wasted. For a 10-person team at $100/hour, that’s $33,000/month in lost productivity.
Real-World Results
Using the Signal-to-Noise Framework, here’s how the tools compared:
| Metric | CodeRabbit (3 PRs) | LlamaPReview (3 PRs) |
|---|---|---|
| Total comments | 14 (1+10+3) | 18 (6+6+6) |
| Tier 1/Tier 2 findings | 3 | 7 |
| Signal Ratio | 21% | 61% |
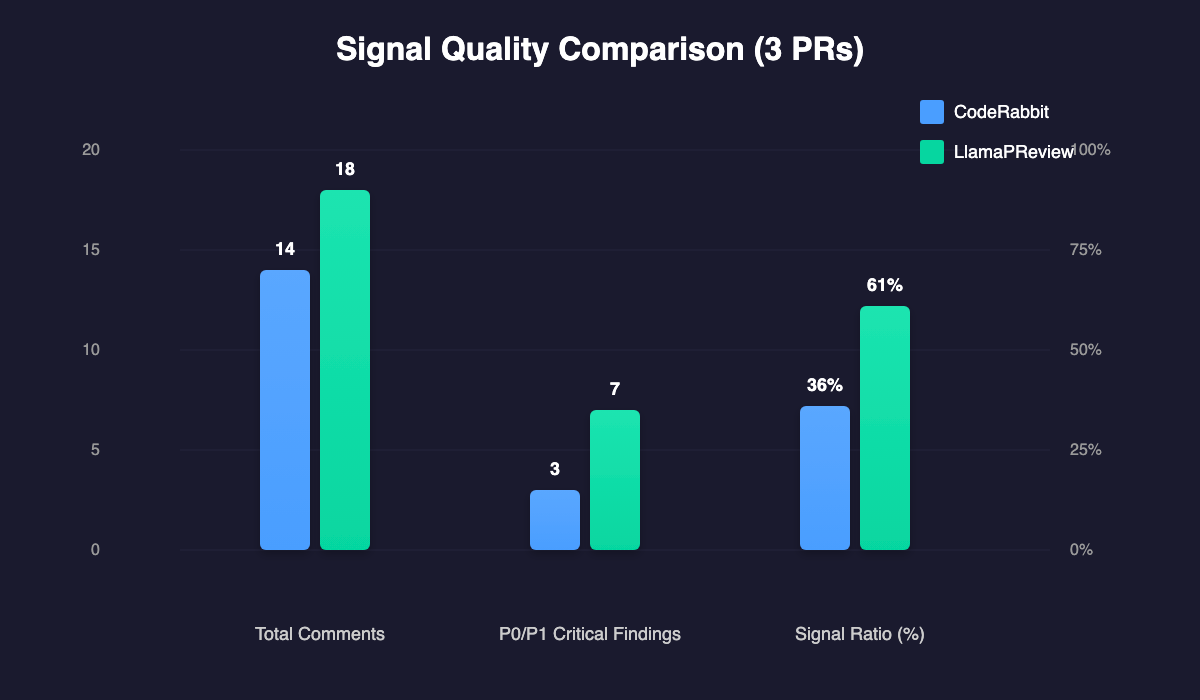 Visual comparison: more comments doesn’t mean better reviews - signal-to-noise ratio matters
Visual comparison: more comments doesn’t mean better reviews - signal-to-noise ratio matters
How to Evaluate Your Current Tool
Use the Signal-to-Noise Framework to evaluate your current AI code review tool. Ask:
- What percentage of comments are actionable?
- Are critical issues buried under noise?
- Does the tool prioritize impact over volume?
Conclusion: The Real Challenge
The future of AI code review isn’t about more comments. It’s about better comments.
By focusing on signal-to-noise ratio, we can build tools that save developers time, catch critical issues, and improve team velocity.
If you’re interested in seeing how this works in practice, LlamaPReview totally free & available for public repositories: LlamaPReview
References
[1] Qodo.ai (2025). “AI Code Review and the Best AI Code Review Tools in 2025.” Research on false positive rates in AI code review tools. Available at: https://www.qodo.ai/blog/ai-code-review/
[2] arXiv (2025). “Rethinking Code Review Workflows with LLM Assistance.” Large-scale study analyzing 22,000+ AI code review comments across 178 repositories. Available at: https://arxiv.org/pdf/2505.16339
[3] Medium (2024). “Context-Aware Code Review: Moving from Static Checks to Intelligent Risk Analysis.” Analysis of signal vs noise in code review tools. Available at: https://medium.com/@saikakarla97/context-aware-code-review-moving-from-static-checks-to-intelligent-risk-analysis-d87f6e6b3b88
[4] CodeAnt.ai (2024/2025). “Are Your Code Reviews Helping or Hurting Delivery?” DORA research program findings on code review impact. Available at: https://www.codeant.ai/blogs/code-review-signals
[5] LlamaPReview (2025). Internal case study analysis of three production PRs (#3044, #3005, #2999) from the bluewave-labs/checkmate repository. Repository available at: https://github.com/bluewave-labs/checkmate
Thoughts on AI coding or repository intelligence?
Let’s connect — LinkedIn.