Vibe Coding Is Not Prompting. It Is Governance.
After building DocMason with AI agents, I stopped treating vibe coding as prompt craft. The durable layer is repository governance: Dao, Fa, Qi, Shu, AGENTS.md, skills, planning, verification, and closeout.

I used to think the hard part of vibe coding was learning how to talk to the model.
Better prompts. Better context dumps. Better reminders. Better tricks for making the agent “understand” what I meant.
After building DocMason and then using agents to build the next Mac app layer around it, I changed my mind.
The hard part is not prompting. The hard part is governance.
If an AI coding agent can read files, edit code, run tests, spawn subtasks, and keep working for an hour, then the prompt is no longer the system. The repository is the system. The question becomes: what does the repository make legal, repeatable, reviewable, and hard to forget?
That is the layer I now care about.
The Problem With Vibe Coding Tips
The internet is full of useful AI coding advice:
- keep an
AGENTS.md - write better custom instructions
- use specs before implementation
- ask the agent to plan first
- keep tasks small
- add tests
- turn repeated workflows into skills
None of that is wrong.
OpenAI’s Codex docs now treat AGENTS.md as durable project guidance, and recommend turning repeated work into skills. GitHub Copilot has its own repository custom instructions. Projects like Agent OS, BMAD, and Spec Kit are all circling the same idea: code generation needs more structure than a chat box.
But a lot of advice still stops at the surface.
It tells you what files to add, not what those files should govern. It tells you to write a spec, but not where that spec sits when it disagrees with product law. It tells you to use an agent skill, but not how that skill should evolve after a task exposes a better rule. It tells you to run tests, but not how to make the verification record durable enough for the next agent.
That gap is where AI coding turns messy.
The agent may produce correct code today, but the system does not learn. The same decision gets re-argued next week. A workaround becomes a convention. A convention becomes folklore. A future agent reads half the repo, misses the real constraint, and confidently creates a second truth.
That is not a prompting failure. That is a governance failure.
My Frame: Dao, Fa, Qi, Shu
I ended up using four concepts from Chinese intellectual tradition:
- Dao: the direction and principles
- Fa: the law and boundaries
- Qi: the apparatus that makes the law operable
- Shu: the concrete techniques and implementation moves
I deliberately keep the names as Dao, Fa, Qi, and Shu.
If I translate them into “strategy, rules, tools, tactics”, the hierarchy collapses into ordinary management vocabulary. The original terms preserve a useful tension. Dao is not a backlog. Fa is not a checklist. Qi is not just tooling. Shu is not random implementation detail.
Together, they describe a development operating system.
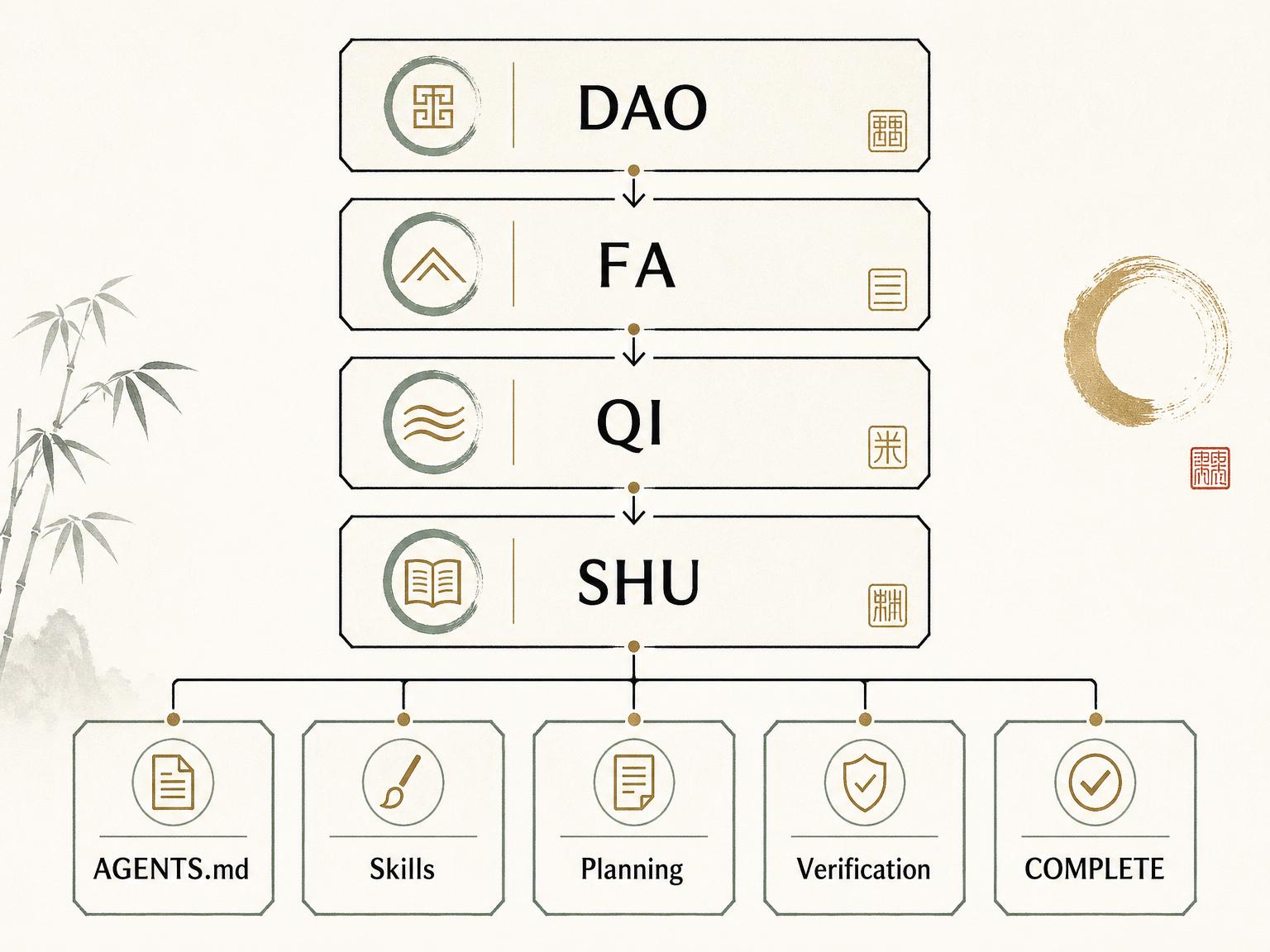 The stack is intentionally simple: higher law constrains lower execution, and lower execution feeds learning back upward.
The stack is intentionally simple: higher law constrains lower execution, and lower execution feeds learning back upward.
In my current repos, this is how the stack maps to real files.
Dao lives in design principles. It answers: what must remain true even if the model changes, the UI changes, or the implementation changes?
For DocMason, Dao includes ideas like:
- the repo is the app
- Codex is the runtime
- answers must be traceable
- private work files stay local
- deterministic evidence matters more than impressive prose
For the Mac app companion, Dao changes shape:
- the app is a companion, not a second runtime
- it must not create a second general ask surface
- it should feel native, calm, and non-geek
- it should hide developer mechanics from non-technical users without lying about what happened
Fa defines legal behavior.
It says which boundaries are non-negotiable. It decides whether a task can start from code, whether it needs a governing planning note first, which files need owner approval, what counts as completion, and what must never be silently redefined by implementation.
In the Mac app repo, Fa classifies work into four task classes:
T0 mechanical: small wording or formatting workT1 bounded implementation: a small change inside settled lawT2 design-affecting work: UX, architecture, or workflow interpretationT3 law-affecting work: changes to Dao, Fa, Qi, or technical doctrine
That classification matters. A T1 task can move fast. A T2 task must plan first. A T3 task can be researched by an agent, but the law files need owner confirmation before editing.
This is where vibe coding starts to feel less like roulette.
Qi is the apparatus.
It includes:
AGENTS.mdas the first-contact contract- canonical skills as reusable workflow contracts
planning/as the governance registry- host adapter layers such as
.agents/skills/ - validation rules
- closeout checks
- future automation
Qi is the difference between “we have principles” and “the agent actually knows what to do on Tuesday afternoon.”
Shu is the implementation discipline.
It decides how real slices move:
- classify the task
- attach or create the governing note
- implement the smallest durable slice
- run the verification that can falsify the change
- write a COMPLETE note with the real commands and real gaps
- harvest durable learning back into the right law surface
That last step is important.
Most teams treat a task as done when the code works. In an AI-native repo, the task is not done until the repository has learned what the task taught.
What This Looks Like In Practice
The first version of this system grew out of DocMason.
DocMason is a local-first, provenance-first knowledge base for serious work files. The operating pattern is unusual: the repo is the application surface, and the agent is the runtime. Codex opens the repo, reads canonical skills, prepares the workspace, builds a knowledge base, retrieves evidence, traces answers, and leaves auditable artifacts behind.
That forced a strong governance model.
If the agent is the runtime, then the repo must carry the runtime law. It cannot depend on one lucky chat transcript. It cannot assume I will remember to remind the model about provenance, workspace state, adapter drift, or answer closure every time.
So DocMason grew:
- a minimal
AGENTS.md - canonical skills
- adapter layers for compatible hosts
- planning law
- runtime artifacts
- validation and trace rules
- completion rules
When I started building the native Mac app companion, I reused the pattern but changed the target.
The Mac app is not a document runtime. It is a companion around DocMason core. That meant I needed a development governance system, not just a product runtime system.
The resulting repo now has:
- a small
AGENTS.mdthat routes future agents into the right workflow - a six-part
planning/Design/stack - an intake skill
- a repo-development skill
- a problem-triage skill
- a seed-corpus supersession log
- dated tech specs
- COMPLETE notes
- adapter integrity checks
- closeout checks
- note scaffolding
- a simple eval runner
This is not glamorous. It is also exactly the point.
The real advantage is not that the agent writes code faster. The real advantage is that future work starts from a coherent operating system instead of a blank chat box.
The Proving Slice
I do not trust frameworks that only work in diagrams.
So I forced the Mac app governance stack through a real proving slice: the first-run workspace selection flow.
The task was small but real. It touched SwiftUI onboarding, workspace provisioning, tests, user-facing copy, accessibility expectations, and product law around the default workspace location.
The loop looked like this:
- The task was classified as design-affecting work.
- A dated tech spec was written before code.
- The implementation stayed inside the slice-size cap.
xcodebuild buildpassed.xcodebuild testpassed with 11 tests.- The COMPLETE note recorded the exact commands.
- The note also recorded honest gaps: live light/dark screenshots and VoiceOver testing were not captured in that session.
- The harvest step identified follow-ups: UI snapshot testing, live UI review procedure, and first-run DocMason core acquisition.
That honest gap is not a failure of the framework. It is the framework doing its job.
The point is not to pretend every task is perfectly verified. The point is to make it impossible for the agent to quietly claim verification that did not happen.
Why This Beats Prompting Alone
Prompts decay.
They live in chat history, in a developer’s memory, in a README paragraph that nobody updates, or in a custom instruction that grows until the model starts skimming it.
Repository governance compounds.
Every recurring correction becomes a rule. Every repeated workflow becomes a skill. Every non-trivial slice leaves a closure artifact. Every durable lesson has a path upward into Dao, Fa, Qi, technical doctrine, or AGENTS.md.
That changes the shape of AI coding in five ways.
First, the agent’s context becomes selective. It does not need to read the whole repo to know where law lives.
Second, verification becomes falsifiable. A COMPLETE note must say what command ran and what happened.
Third, host portability improves. Codex, Copilot, and future hosts can have thin adapter layers, while canonical truth stays in one place.
Fourth, design decisions stop hiding inside code diffs. If a UI change redefines product behavior, it needs a governing note.
Fifth, the system learns. Not in a vague “memory” sense, but in a concrete repository-surface sense.
That is the part I think many vibe coding discussions still miss.
The goal is not to make the model smarter through longer prompts. The goal is to make the environment more lawful, so a smart model has less room to drift.
What I Would Not Copy Yet
I am not claiming everyone should adopt my exact stack.
For many projects, Dao/Fa/Qi/Shu will feel too heavy. If you are building a weekend prototype, you probably do not need constitutional law. If your repo has one developer, one screen, and no serious reliability bar, a short AGENTS.md plus tests may be enough.
The full stack is useful when several things are true:
- the project has real product law
- agents will work across many sessions
- implementation decisions affect future architecture
- reliability matters more than raw generation speed
- the owner wants the repo to become smarter over time
The stack also has risks.
If high law is wrong, the agent will follow the wrong law. If the documents become bloated, the system turns into bureaucracy. If every tiny edit requires a planning note, velocity dies. If the owner never harvests learning upward, the framework becomes decorative.
This is why I do not think the next step is to open-source a generic tool immediately.
The better next step is to show the method, let people react, and then decide whether a starter kit, template repo, or lightweight CLI is actually worth extracting.
A Minimal Version Worth Trying
If I were adding this to a serious AI-native repo from scratch, I would start with five things.
1. Keep AGENTS.md small.
Use it for first contact: identity, routing, hard boundaries, and where to read next. Do not turn it into a book.
2. Turn repeated prompts into skills.
If you keep asking the agent to follow the same debugging flow, review checklist, migration process, or release procedure, it should become a skill.
3. Add one law layer above implementation.
Call it whatever you want. I use Dao and Fa because the distinction matters to me. The important part is that product principles and legal behavior live above task specs.
4. Require COMPLETE notes for non-trivial work.
Not long reports. Just enough to record:
- what changed
- what was verified
- what command actually ran
- what gaps remain
- what learning should be promoted
5. Add one mechanical drift check.
Start simple. Check that every dated tech spec has a matching COMPLETE note. Check that adapter skills resolve. Check that generated mirrors are not hand-edited. The first useful automation is usually boring.
That is enough to change the feel of the repo.
The Takeaway
Vibe coding is often described as a style of programming.
I think that undersells it.
At higher autonomy, vibe coding becomes a governance problem. The agent is not just completing lines. It is making design moves, choosing evidence, editing interfaces, and creating future constraints.
If you do not give it law, it will infer law from whatever context happens to be nearby.
My current answer is Dao, Fa, Qi, Shu:
- Dao keeps the project oriented.
- Fa keeps behavior legal.
- Qi makes the law operable.
- Shu turns it into working code.
This is still evolving. I do not know yet whether it should become a public tool, a starter kit, or just a pattern I keep refining inside my own repos.
But I am now convinced of one thing:
The future of serious AI coding is not better prompting. It is better repository governance.
If you are building in this direction, I would be curious where you draw the line: what belongs in repo law, and what should stay in chat?