I Built repo-graph-rag Before the Code Graph Wave
In early 2025 I started repo-graph-rag to build token-free, traversable repository intelligence. The recent code-graph wave validates the problem, but also explains why I moved upstream anyway.
Watching code-review-graph take off recently clarified something for me.
The problem I was working on in early 2025 was real. The market had simply not learned how to see it yet.
This is not a claim that I built the winning product first. I did not. Markets do not reward architecture alone. They reward timing, interfaces, packaging, distribution, and whether the surrounding ecosystem makes an idea legible.
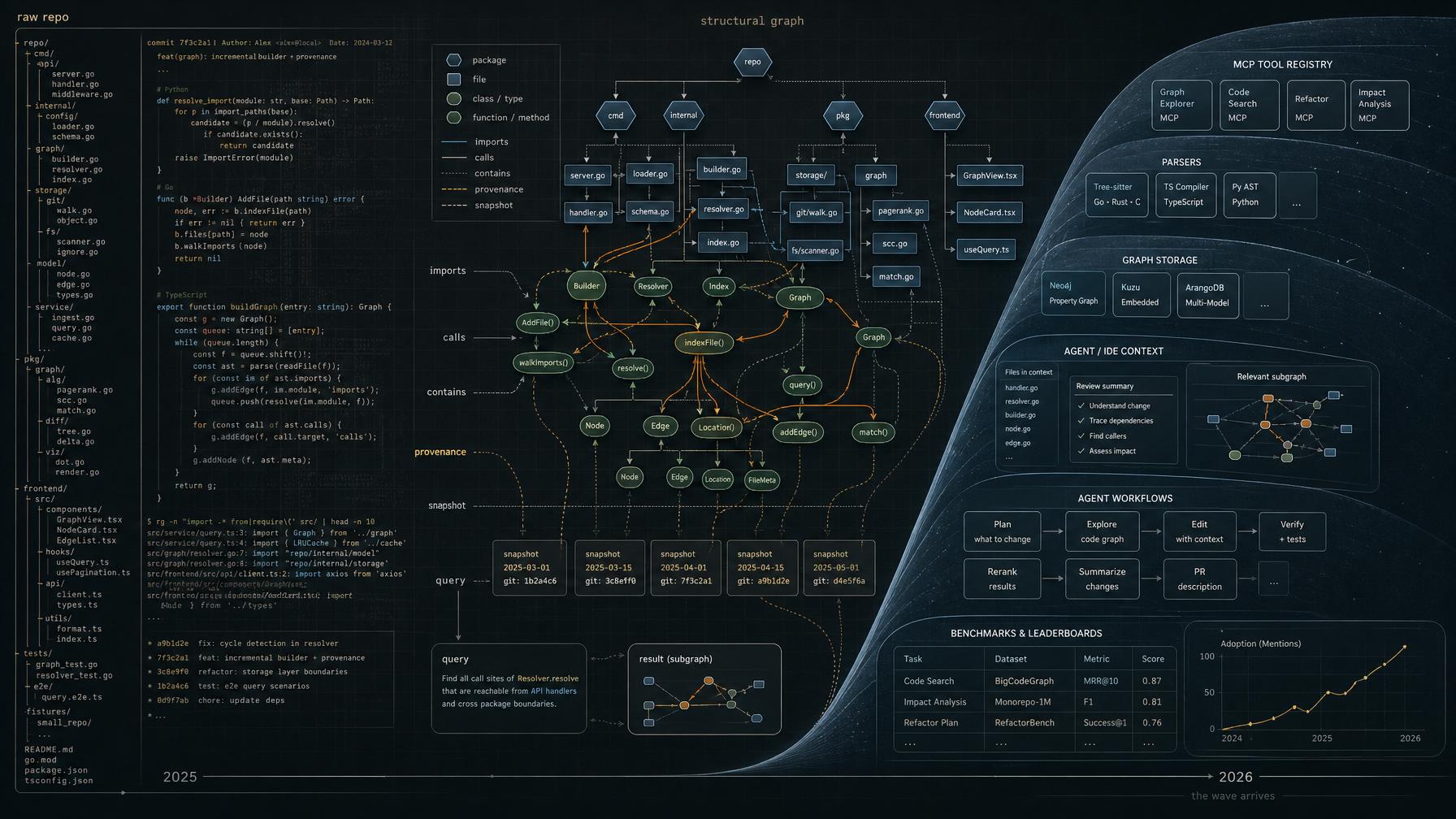
Back then I was building repo-graph-rag. The core idea was straightforward: large repositories cannot be understood by repeatedly shoving raw source files into an LLM context window. That is not repository intelligence. That is expensive amnesia.
If you want serious repository analysis, you need a structural substrate that can be built without spending LLM tokens just to rediscover the repository, maintained as the code changes, and traversed like a graph instead of reread like a book.
The graph itself was never the point. The point was to stop rebuilding repository structure from scratch every time a model needed to reason.
What I Was Trying To Solve
I came to this through code retrieval and code review.
Projects like llama-github and LlamaPReview taught me the same lesson from different angles. Retrieval could surface relevant code. Review could comment on diffs. Both were useful. But both kept running into the same wall: the system had to rebuild understanding over and over again from unstable slices of context.
Later I started calling that failure mode context instability.
By the time I began repo-graph-rag, I was no longer interested in making the model a little better at rereading repositories from scratch. I wanted a substrate that could carry repository structure outside the model’s temporary context window.
That meant four things mattered to me from the beginning:
- the graph should be built from source structure, not from an LLM summary of the source
- the graph should support traversal, so repository understanding can move through imports, calls, containment, and other relations instead of flattening the whole repo into one prompt
- the graph should be maintainable as the codebase changes, otherwise it never becomes daily infrastructure
- the graph should be inspectable enough that an engineer can ask why a node or edge exists
This is also why I never found the “just put the whole repo into context” story convincing. A large repository is not something to stuff wholesale into a model. It is something to traverse.
I did not want to pay LLM tokens every time I needed to rediscover that one file imported another, that a method call crossed a package boundary, or that a change in one place had a blast radius somewhere else. I wanted the structural layer extracted once, preserved, and queried on demand.
And yes, I believed from early on that this layer needed to be incrementally maintainable.
I later experimented with incremental updating inside the repo. The current OSS artifact explicitly does not present that line as a stabilized public promise, and that restraint matters. But the design requirement itself was obvious long before it became popular: if the structural substrate cannot stay in sync with a moving repository, it remains a research toy.
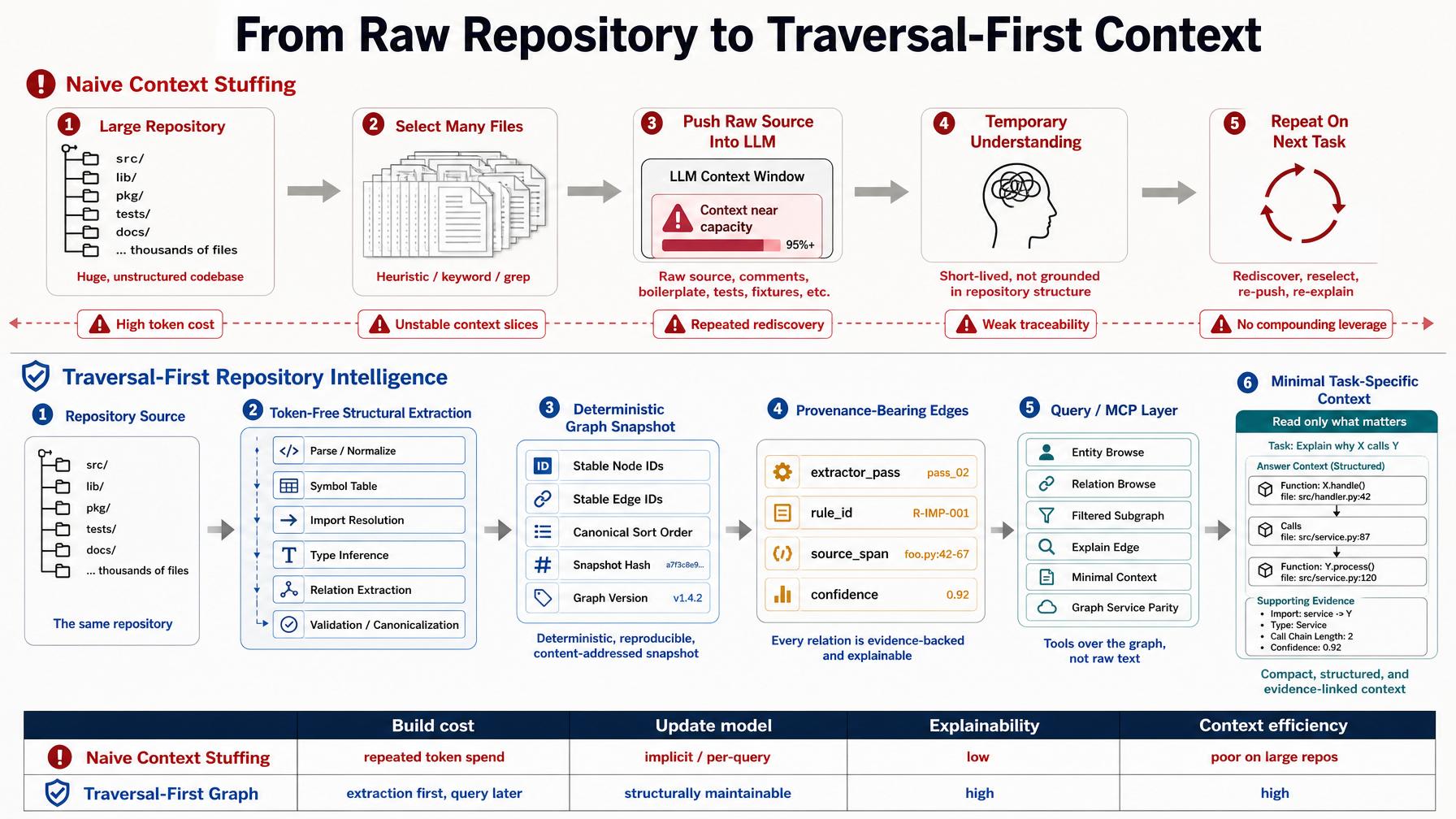 The design target was not “put less code into the prompt.” It was to extract repository structure first, then query it deterministically.
The design target was not “put less code into the prompt.” It was to extract repository structure first, then query it deterministically.
The Public Record Is Still There
I do not need to rely on fuzzy memory or private notes to make that case. The public record is enough.
The first public repo-graph-rag commit landed on March 2, 2025. That first commit was just a README stub. The second added a .gitignore.
The third commit on the same day, though, was the real signal. In 020ecb5, the repo suddenly gained 15 files and 9,278 lines: analyzers, relation extraction, schema, CLI, and the main graph builder body.
That matters because I do not want to argue this in hindsight.
I am not saying, after the fact, that I “had the idea early” in some loose founder-story way. The public repository already showed the shape of the idea on day one.
The work had started even earlier in private notebooks, but I do not need that claim to make the case. The public evidence is already strong enough.
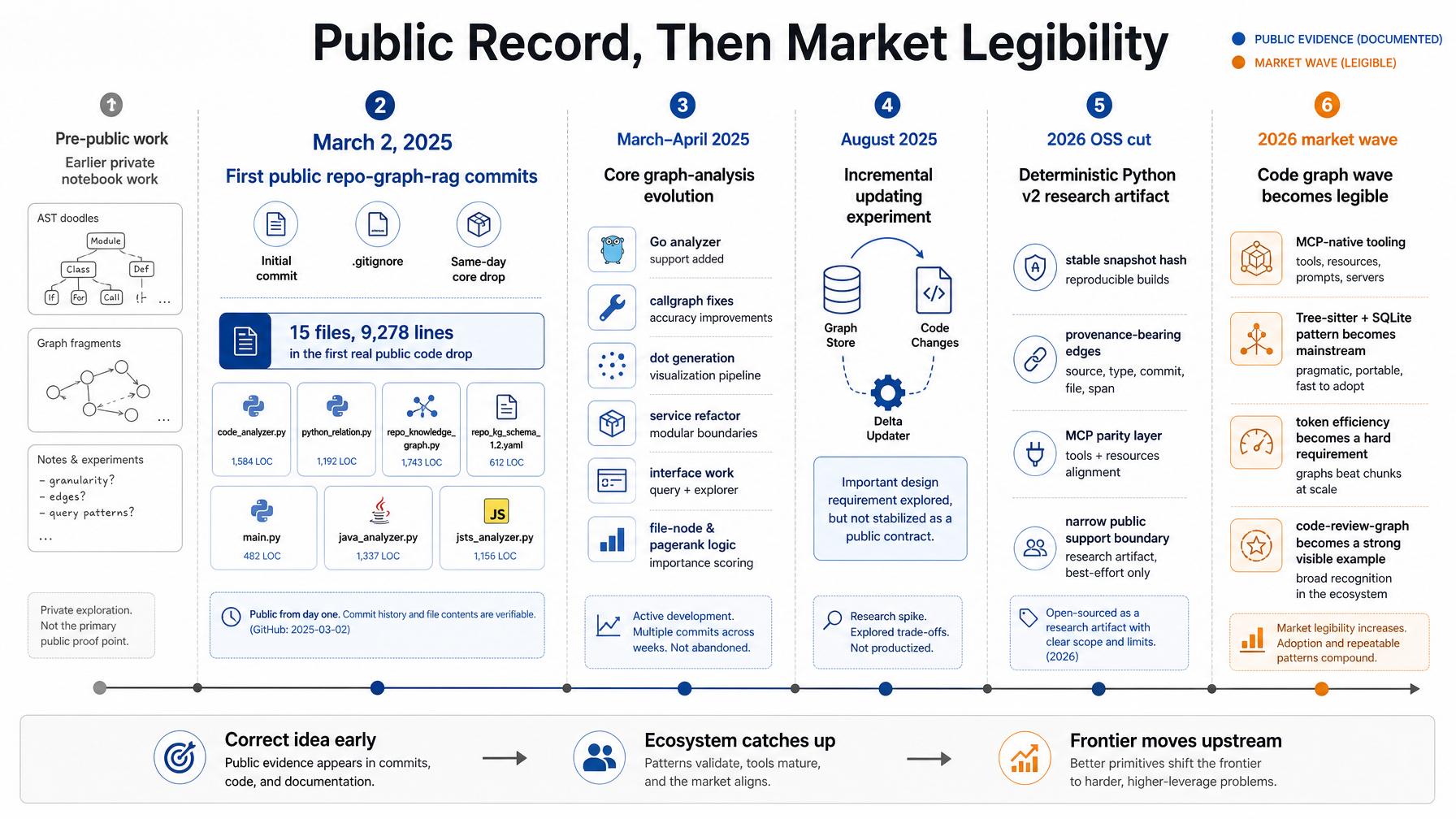 The public proof point is enough: the idea was already visible in code, commits, and structure long before the current wave made it easy to recognize.
The public proof point is enough: the idea was already visible in code, commits, and structure long before the current wave made it easy to recognize.
What repo-graph-rag Actually Optimized For
When people hear “repo graph”, they often imagine a visualization first. That was never my center of gravity.
What I cared about was a deterministic, traversable, evidence-backed structural substrate for repository intelligence.
Even in its current OSS cut, repo-graph-rag still reflects that instinct. The supported Python v2 path centers deterministic snapshots, stable node and edge identity, canonical serialization, and provenance-bearing relations. The committed demo ships with a stable snapshot hash, and the query surface and MCP surface both operate over the same extracted snapshot state.
That detail matters. The same demo can be regenerated to the same content-level artifact, and the edges carry provenance fields such as extractor_pass, rule_id, and source_span. That is much closer to infrastructure than to a one-off visualization.
That may sound overly strict for a research artifact. To me it was just engineering hygiene.
If a graph is going to support real analysis, then “there is an edge here” is not enough. You need to know why the edge exists, which extraction pass produced it, what rule generated it, what source span it came from, and how much confidence you should place in it.
Otherwise the graph becomes just another opaque retrieval layer wearing infrastructure clothing.
This is also why I still care about honest scope.
The current OSS release is intentionally narrow about what it supports. Python v2 is the public mainline. The Go subtree is experimental. The older Arango-backed path is kept as historical compatibility. Incremental updating was explored, but not stabilized as a public contract.
I would rather publish a smaller truth than a bigger marketing story.
That may not be the fastest way to catch a wave, but I still think it is the right way to build technical credibility.
Why The Wave Arrived Now
What I see in the current code-graph wave is convergence.
The problem was real before the market was ready for it.
What changed is that the surrounding stack finally became obvious.
Today the recipe is legible in a way it was not a year earlier: Tree-sitter for structural parsing, local persistence through SQLite or similar stores, MCP as the access protocol for coding agents, watch-mode or hook-based maintenance, and a coding-agent workflow where brute-force context loading suddenly looks wasteful and primitive.
That last part matters most.
When agents were weaker, people tolerated a surprising amount of context waste. Once agents started doing more real work, token economics and context discipline stopped being optional. The market did not suddenly become more technical. The interfaces around the idea matured, and the pain became impossible to ignore.
This is why a project like code-review-graph resonates now. It productizes the need in the shape that 2026 users can immediately feel: blast-radius analysis, minimal context, MCP integration, incremental updates, review workflows, benchmarks, and an installation story that fits the current agent ecosystem.
In early 2025, this class of idea still felt research-shaped.
In 2026, it feels product-shaped.
That is a very different thing.
What The New Wave Validates
At a minimum, the current wave validates three judgments I felt strongly about when I started repo-graph-rag.
First, repository understanding needs structure, not just more context stuffing.
Second, token efficiency is not a cosmetic optimization. It is an architectural requirement once AI systems operate on real repositories at real scale.
Third, graphs only become meaningful when they are tied to everyday developer workflows rather than held at the level of research demos or pretty diagrams.
Those points no longer sound exotic. That alone tells you how much the environment has changed.
What I Still Think The Field Underestimates
At the same time, I think the current wave is still underweighting a few things that will matter more as these systems move from clever tooling to trusted infrastructure.
One is provenance.
If a graph is going to influence refactors, architecture decisions, agent autonomy, or review conclusions, then explainability stops being a nice extra. The graph needs to explain itself.
Another is reproducibility.
The same repository at the same revision should not quietly yield different structural truth because of nondeterministic extraction behavior. Once graphs become part of serious workflows, replayability matters.
The third is scope discipline.
I am naturally skeptical of tools that claim to fully solve everything at once: all languages, all frameworks, all repository shapes, all workflows, all the time. In this category especially, breadth is easy to market and hard to prove.
My instinct has always been that a code graph becomes more valuable when it is inspectable, replayable, and honest about its limits, not merely queryable.
The field may still need a few cycles to relearn that.
Why I Moved On Anyway
The current code-graph wave validates the original problem, but it also validates my decision not to keep betting everything on that exact product surface.
By the time coding agents became good enough for code graphs to explode, the frontier had already moved again.
The scarce problem was no longer just reviewing code after generation. It was governing the environment before generation: context, constraints, evidence, interfaces, state, and the operating surface the agent is allowed to act inside.
That is why my work moved upstream.
It first moved toward DocMason, where the hard problem is no longer source code alone, but messy private knowledge environments full of decks, spreadsheets, PDFs, and email-shaped evidence.
And it keeps moving toward deterministic output systems, where the question is not only how to understand serious knowledge work, but how to turn that understanding into native, usable deliverables.
The substrate problem never disappeared.
It just got bigger than code.
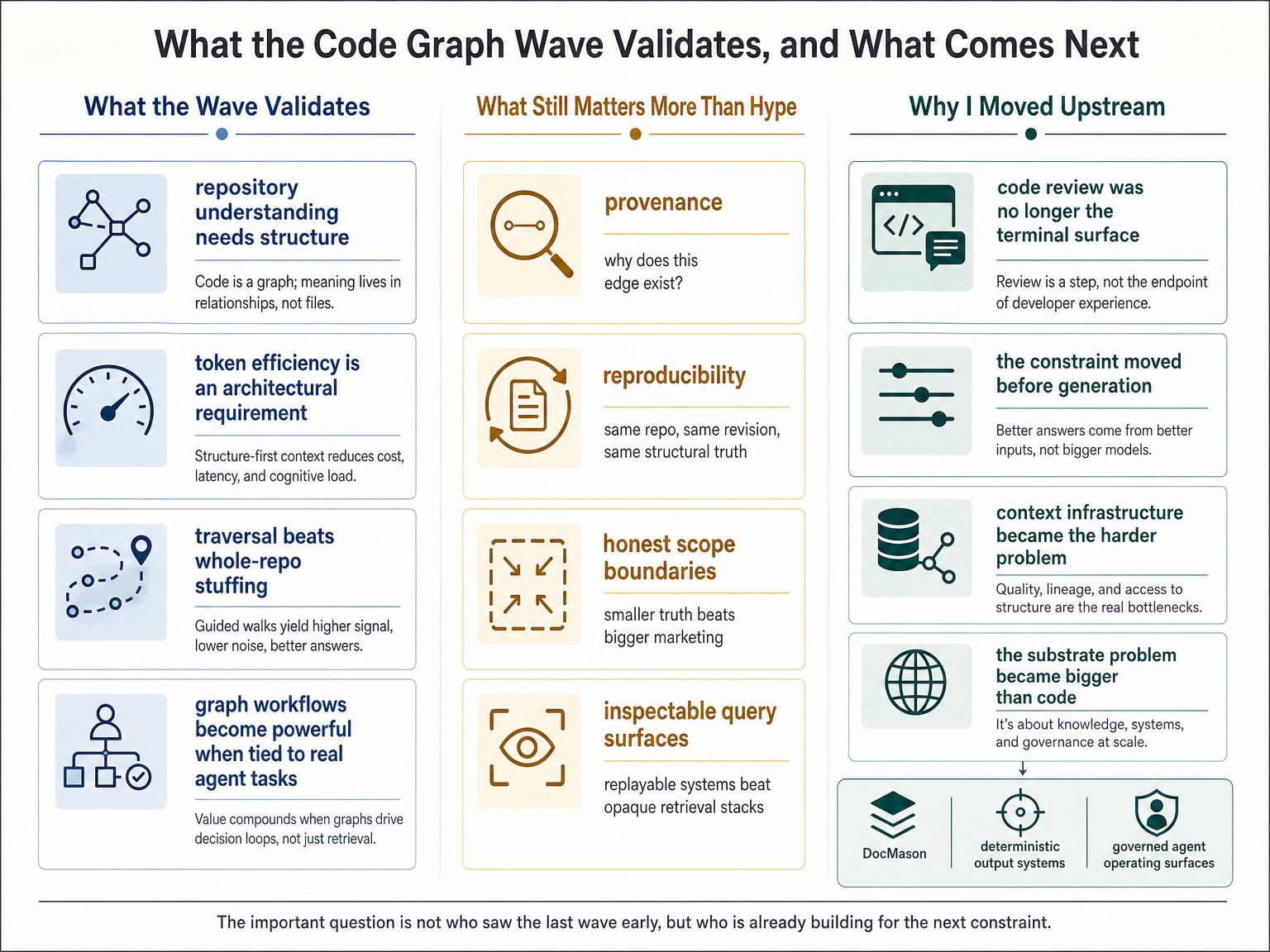 The code-graph wave validates the substrate problem. It does not end it.
The code-graph wave validates the substrate problem. It does not end it.
The Interesting Part Is Not That I Was Early
So yes, I was early on repo graphs, but that is not the interesting part.
Being early is a biographical detail. The interesting part is why the idea made sense before it became fashionable, why the market only recently learned how to see it clearly, and why the next constraint was already visible from inside the same line of work.
An infrastructure idea can be technically correct, publicly visible, and still arrive before the surrounding ecosystem makes it legible.
That is what I think happened here.
Watching the current wave does not make me want to complain. It makes me want to keep doing the same thing I was trying to do then: look one constraint ahead.
The market has now learned how to see this problem. The more interesting question is which infrastructure constraints still look niche only because the interfaces around them have not matured yet.