The Death of the God Model: Why True AGI Requires a Split Brain Architecture
The AI industry's pursuit of a single omnipotent God Model is a dead end. Due to the mathematical paradoxes of RLHF and alignment, models are inevitably bifurcating into specialized hemispheres—and the future belongs to Agentic Frontal Lobe orchestration.
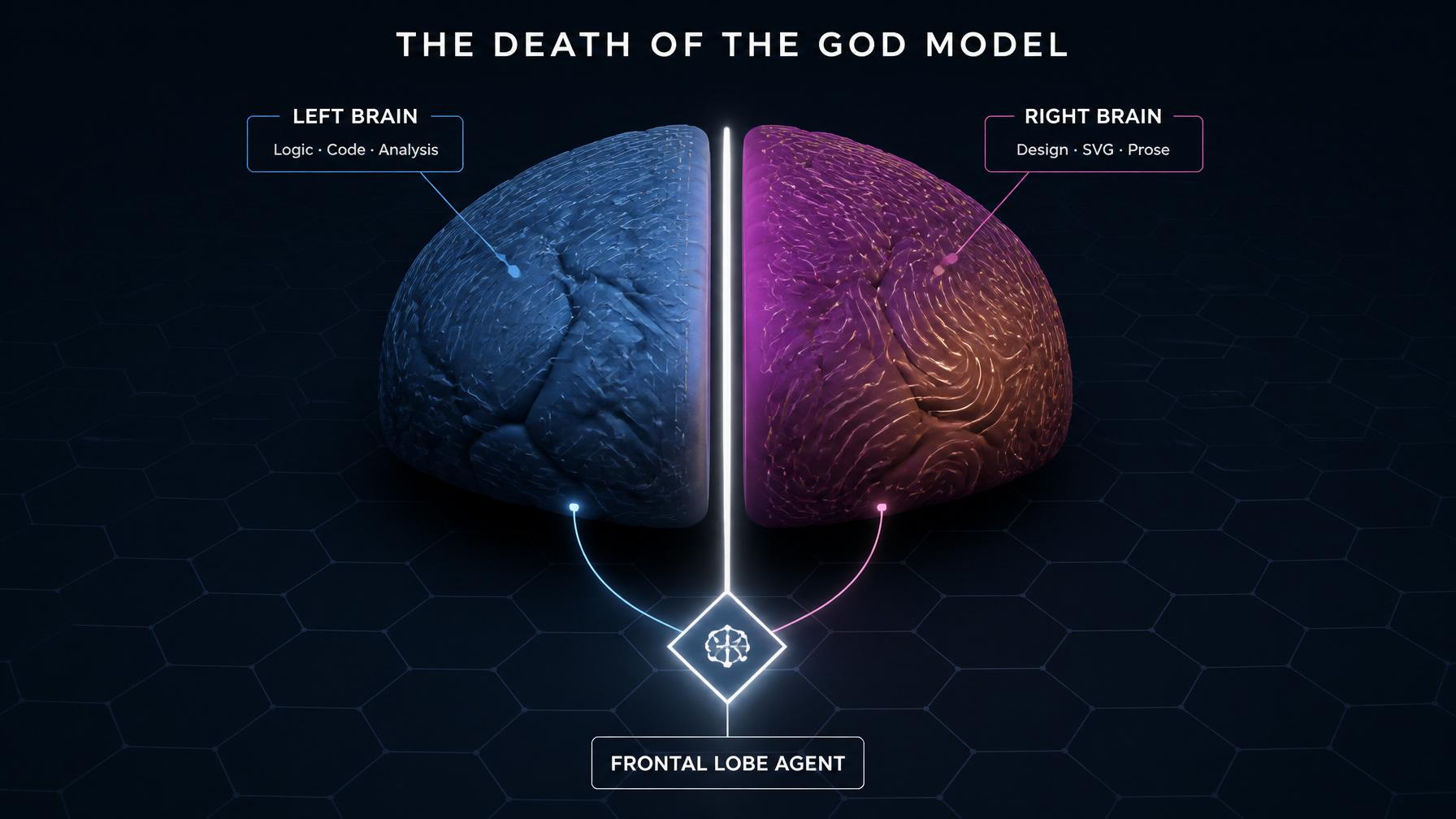
TL;DR: The AI industry’s pursuit of a single, omnipotent “God Model” is a dead end. Due to the mathematical paradoxes of RLHF and alignment, models are inevitably bifurcating into specialized hemispheres. We are seeing the rise of the “Left Brain” (GPT-5.5 / Opus 4.8 for logic, backend coding, and deep analysis) and the “Right Brain” (Gemini 3.1 Pro / Opus 4.6 for SVG design, PPTs, aesthetics, and creative writing). The future of AGI isn’t one massive neural network; it is an Agentic Frontal Lobe orchestrating these highly biased, specialized models.
Update — July 15, 2026: Anthropic Measures Model-Level Behavioral Divergence
On July 13, Anthropic published Claude’s Values Across Models and Languages, a research report analyzing 309,815 subjective Claude.ai conversations across Sonnet 4.6, Opus 4.6, and Opus 4.7 in 20 languages. It found small but structured differences in expressed values: Sonnet 4.6 leaned warmer and more deferential, while Opus 4.7 leaned more cautious, rigorous, deep, and candid. Four value axes accounted for 15% of the variation after controlling for task, topic, and user-expressed values.
This provides independent evidence for one narrow premise of this essay: frontier models can develop measurably different behavioral defaults rather than converging on a single profile. The original version of this essay was publicly committed on June 3, before Anthropic’s report.
The report does not establish the stronger claims made here. It is observational rather than a same-prompt randomized comparison; it measures value expression, not task capability or work-product quality; and it does not test routing or heterogeneous orchestration. The result strengthens the empirical motivation for studying specialization. The case for a split-brain architecture still requires controlled, task-level evidence.
Preface: The Research Behind This Post
Before writing this deep-dive, I conducted an extensive community sentiment and technical benchmark survey across the mid-2026 frontier model ecosystem—primarily covering Anthropic’s Claude Opus series, OpenAI’s GPT-5.5, and Google’s Gemini 3.1 Pro.
The trigger: a paradox that defies industry intuition. As 2026’s latest generation of frontier models arrived, I observed an extremely abnormal phenomenon: benchmark scores keep climbing higher and higher, yet developer and creator community feedback has fractured into irreconcilable camps. People no longer use one model for everything. Instead, they loudly complain about specific regressions and rigidity in newer models. This prompted me to dig into the real use cases and underlying logic.
The core finding: the “STEM vs. Humanities” split in LLMs. Through deep retrieval and cross-validation across Reddit (r/ClaudeAI, r/ClaudeCode), Hacker News, DataCamp, and various developer communities, I found that current frontier model capabilities have developed an unmistakable “left brain / right brain” divergence—and the technical reasons why this is structurally inevitable.
The Paradox No One Wants to Name
If you spend enough time reading developer forums and creator subreddits right now, you’ll notice a glaring paradox.
It is mid-2026. We have access to the most capable frontier models in history: Claude Opus 4.8, GPT-5.5, and Gemini 3.1 Pro. By every traditional metric, these models are absolute monsters. But talk to the people actually using them in production, and the sentiment is entirely fractured.
Over on Reddit, the r/ClaudeAI community is actively mourning the loss of Opus 4.6. You see posts complaining that Opus 4.8 has become an insufferable, overly-critical pedant, completely ruining creative writing. Meanwhile, over in r/ClaudeCode, developers are praising that exact same model (4.8) as the ultimate autonomous bug-hunter.
We see the exact same divergence between OpenAI and Google. Recent developer tests show that GPT-5.5 absolutely crushes complex research, multi-step reasoning, and backend scope implementation. It is a logic machine. Yet, when you ask it to design a beautiful presentation or code an animated UI component, it feels rigid and corporate.
Enter Gemini 3.1 Pro. While it might struggle to autonomously debug a complex Python backend without hallucinating, frontend developers are noting that its ability to generate clean, CSS-animated SVGs, design PPT structures, and handle multimodal aesthetic tasks is currently unmatched. Gemini 3.1 Pro is, for all intents and purposes, a humanities and arts major.
For the last three years, the entire AI industry has been chasing the “God Model”—a monolithic neural network that can paint a soul-stirring masterpiece, and then flawlessly debug a 100,000-line C++ repository.
I don’t think the God Model is happening. In fact, the underlying math of how we train these models suggests it is structurally impossible.
The RLHF Zero-Sum Game
To understand why models are losing their generalist charm, we have to look at the post-training phase, specifically RLHF (Reinforcement Learning from Human Feedback).
 RLHF forces a single latent space to choose between deterministic truth-seeking and empathetic exploration. You cannot have both at maximum capacity.
RLHF forces a single latent space to choose between deterministic truth-seeking and empathetic exploration. You cannot have both at maximum capacity.
This is the RLHF Zero-Sum Game. You cannot optimize a single latent space for both “ruthless, deterministic truth-seeking” and “empathetic, vibe-based exploration.”
In information theory terms, backend coding and logic require low entropy. There is only one correct way to structure a database query. RLHF trains the model to collapse its probability distribution around the single highest-confidence answer.
But creative writing, SVG art, and slide design require high entropy. The beauty of design lies in ambiguity, metaphor, and deviating from the most probable next token. If you reward a model for pointing out logical flaws in a Python script, it will apply that exact same critical, low-entropy lens to your creative tasks. You are training a compliance officer, and then asking it to be an Art Director. It doesn’t work.
The MoE Illusion: Why “Experts” Can’t Fix Personality
At this point, a machine learning engineer will usually interject: “Wait, doesn’t a Mixture of Experts (MoE) architecture solve this? Can’t we just have a coding expert and an art expert inside the same model?”
The answer is no. MoE segregates knowledge, but RLHF homogenizes personality.
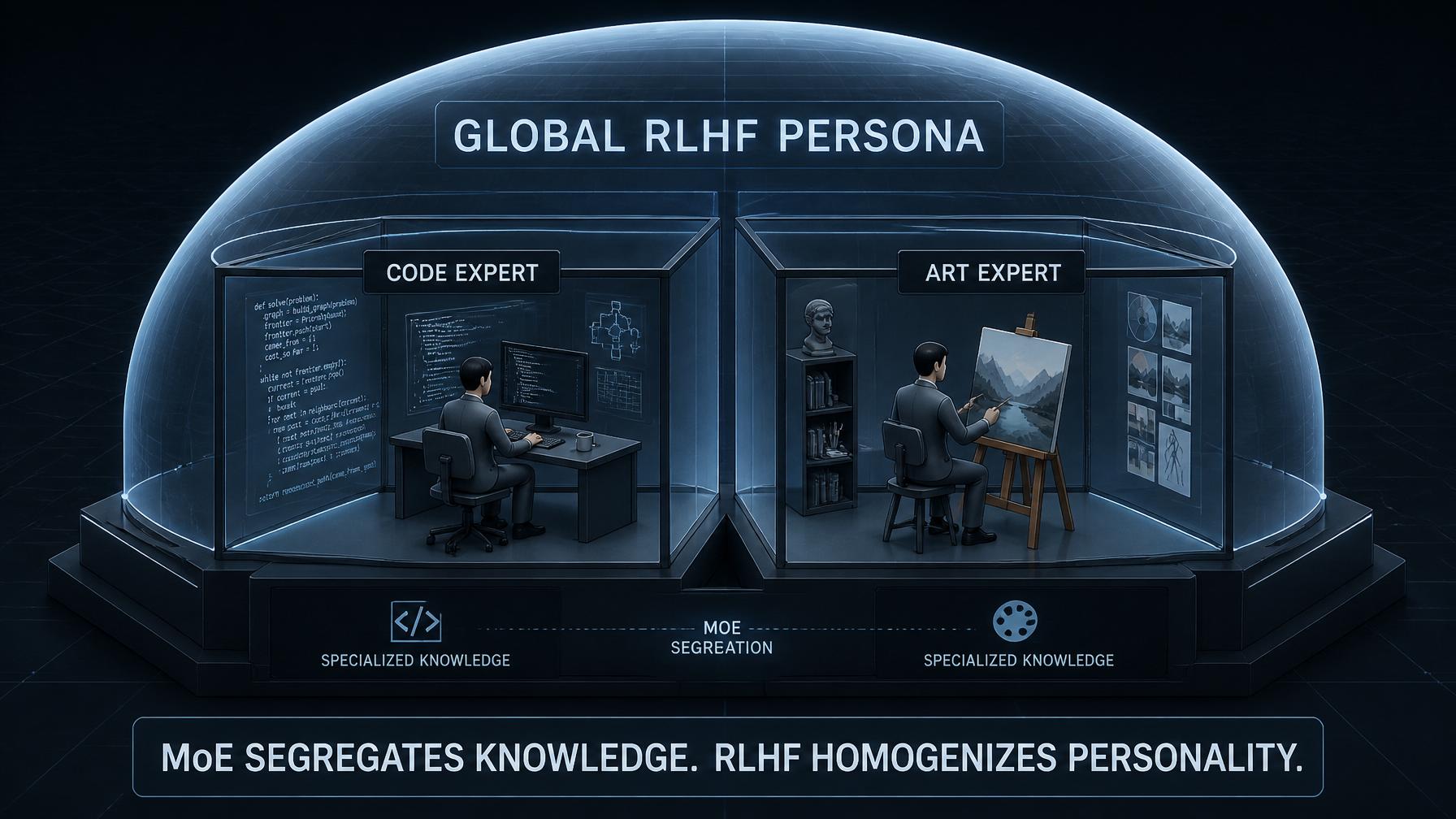 In a standard MoE architecture, Feed-Forward Networks are split into specialized experts, but the Attention layers and the RLHF reward signal remain shared and global.
In a standard MoE architecture, Feed-Forward Networks are split into specialized experts, but the Attention layers and the RLHF reward signal remain shared and global.
In a standard MoE architecture, the Feed-Forward Networks (FFNs) are split into specialized experts, but the Attention layers are typically shared. More importantly, during the final RLHF or DPO (Direct Preference Optimization) alignment phase, the model is penalized and rewarded as a single, global entity.
The Reward Model injects a global “persona” into the weights—usually one that is helpful, harmless, and highly analytical. So, when your prompt gets routed to the “SVG/Design expert” inside GPT-5.5, that expert still speaks with the overarching voice of a cautious, analytical engineer. The router can direct the tokens, but it cannot change the fundamental vibe of the network.
MoE is a micro-solution to a macro-problem.
The Great Bifurcation: STEM vs. Humanities
Because AI labs cannot solve this objective-function conflict within a single set of weights, the market is naturally splitting. We are seeing the rise of specialized foundational models:
1. The “Left-Brain” Models (STEM & Execution)
- Traits: Low temperature, highly analytical, self-correcting, deeply suspicious of edge cases.
- Current Examples: GPT-5.5 (the ultimate logic and research engine) and Opus 4.8 (the autonomous SWE).
- Use Cases: Backend architecture, complex data analysis, multi-step reasoning, and autonomous tool use.
2. The “Right-Brain” Models (Humanities & Aesthetics)
- Traits: High aesthetic intuition, multimodal fluency, tolerant of ambiguity, masters of visual layout and subtext.
- Current Examples: Gemini 3.1 Pro (the king of SVGs, PPTs, and visual frontend) and the much-missed Opus 4.6 (the master of prose).
- Use Cases: Creative writing, UI/UX aesthetic direction, animated SVG generation, presentation design, and artistic brainstorming.
The Future Architecture: The Agentic Frontal Lobe
If no single model can do it all, how do we achieve true AGI-level workflows?
The answer is Agentic Orchestration—essentially, building a Macro-MoE at the application layer. The future of AI isn’t a single prompt to a single API endpoint. It will look exactly like a biological brain.
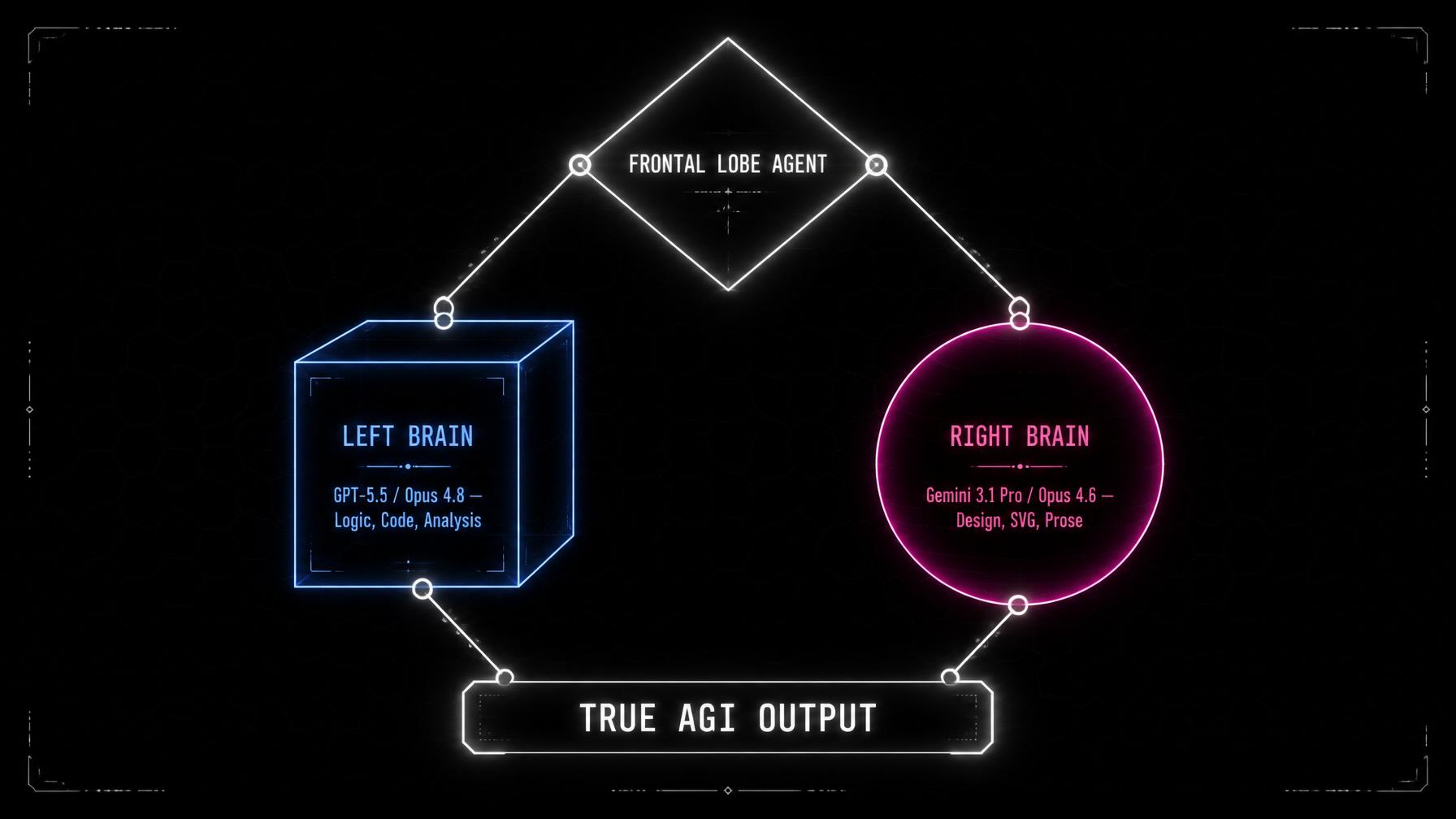 The Frontal Lobe Agent acts as a lightweight, highly logical router that decomposes complex goals and delegates to the specialized hemispheres.
The Frontal Lobe Agent acts as a lightweight, highly logical router that decomposes complex goals and delegates to the specialized hemispheres.
You will have a “Frontal Lobe” Agent—a lightweight, highly logical router—that breaks down your complex goal and delegates it to the specialized hemispheres.
Imagine building a modern web application in late 2026:
- You tell your Frontal Lobe agent your vision.
- The orchestrator sends the UI layout, CSS animations, SVG assets, and copywriting to a Right-Brain model (Gemini 3.1 Pro or Opus 4.6).
- It simultaneously sends the database schema, API routing, and security audits to a Left-Brain model (GPT-5.5 or Opus 4.8).
- The Frontal Lobe then stitches the frontend art and the backend logic together into a cohesive product.
Conclusion: Embrace the Bifurcation
We need to stop complaining that our calculators are bad at painting, and that our artists are bad at doing taxes. The divergence we are seeing in 2026 isn’t a failure of AI scaling; it is the natural maturation of the technology. Intelligence is not a single slider you push to the right.
The companies that win the next era of AI won’t be the ones waiting for a God Model. The winners will be the developers who embrace the bifurcation, wiring together the Left Brain and the Right Brain to build something truly complete.
The “God Model” is dead. Long live the Split Brain.
References & Evidence
The observations in this post are grounded in real developer feedback and benchmarks across the AI ecosystem as of mid-2026:
- Gemini 3.1 Pro’s Visual & Frontend Dominance: Developers noting Gemini’s unmatched ability in generating clean SVG code, CSS animations, and visual layouts.
- GPT-5.5’s Logic & Backend Superiority: Comparisons showing GPT-5.5 crushing complex research, multi-step reasoning, and scope implementation.
- The Opus 4.6 vs 4.8 Creative Divide: Users highlighting how RLHF and “honesty” ruined creative writing in newer models.
- Model-Level Differences in Expressed Values: Anthropic’s large-scale observational analysis found small but structured differences across Claude models.